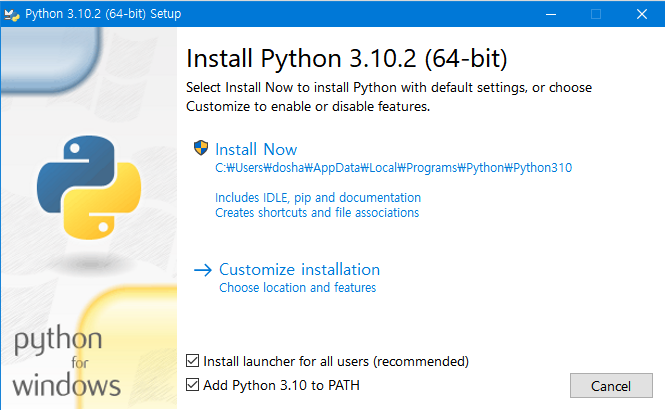
- 이미지 업로드
import cv2
# 이미지 로드
image = cv2.imread('image.jpg')
# 그레이스케일로 변환
gray_image = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
# 변환된 이미지 저장
cv2.imwrite('gray_image.jpg', gray_image)
- 객체 감지와 추적
import cv2
# 분류기 로드
face_cascade = cv2.CascadeClassifier('haarcascade_frontalface_default.xml')
# 이미지 로드
image = cv2.imread('image.jpg')
# 그레이스케일로 변환
gray_image = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
# 얼굴 감지
faces = face_cascade.detectMultiScale(gray_image, scaleFactor=1.1, minNeighbors=5, minSize=(30, 30))
# 감지된 얼굴에 사각형 그리기
for (x, y, w, h) in faces:
cv2.rectangle(image, (x, y), (x+w, y+h), (255, 0, 0), 2)
# 결과 이미지 보여주기
cv2.imshow('Face Detection', image)
cv2.waitKey(0)
cv2.destroyAllWindows()
- 영상 처리와 비디오 분석
import cv2
# 비디오 캡처 생성
cap = cv2.VideoCapture('video.mp4')
while True:
# 프레임 읽기
ret, frame = cap.read()
if not ret:
break
# 그레이스케일로 변환
gray_frame = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)
# 변환된 프레임 출력
cv2.imshow('Video', gray_frame)
# 'q' 키로 종료
if cv2.waitKey(1) & 0xFF == ord('q'):
break
# 리소스 해제
cap.release()
cv2.destroyAllWindows()
- 이미지 분할과 객체 추출
import cv2
import numpy as np
# 이미지 로드
image = cv2.imread('image.jpg')
# 이미지를 HSV로 변환
hsv_image = cv2.cvtColor(image, cv2.COLOR_BGR2HSV)
# 추출할 객체의 색상 범위 정의
lower_range = np.array([0, 50, 50])
upper_range = np.array([10, 255, 255])
# 색상 범위에 맞는 이미지 마스크 생성
mask = cv2.inRange(hsv_image, lower_range, upper_range)
# 마스크를 사용하여 원본 이미지에서 객체 추출
extracted_image = cv2.bitwise_and(image, image, mask=mask)
# 결과 이미지 출력
cv2.imshow('Object Extraction', extracted_image)
cv2.waitKey(0)
cv2.destroyAllWindows()
- 히스토그램 분석
import cv2
import numpy as np
from matplotlib import pyplot as plt
# 이미지 로드
image = cv2.imread('image.jpg', 0)
# 히스토그램 계산
hist = cv2.calcHist([image], [0], None, [256], [0, 256])
# 히스토그램 그래프 생성
plt.plot(hist, color='black')
plt.xlim([0, 256])
plt.xlabel('Pixel Value')
plt.ylabel('Frequency')
plt.title('Histogram')
plt.show()
- 모폴로지 연산
import cv2
import numpy as np
# 이미지 로드
image = cv2.imread('image.jpg', 0)
# 이진 이미지로 변환
ret, binary_image = cv2.threshold(image, 127, 255, cv2.THRESH_BINARY)
# 모폴로지 연산 수행
kernel = np.ones((5, 5), np.uint8)
dilated_image = cv2.dilate(binary_image, kernel, iterations=1)
eroded_image = cv2.erode(binary_image, kernel, iterations=1)
# 결과 이미지 출력
cv2.imshow('Dilated Image', dilated_image)
cv2.imshow('Eroded Image', eroded_image)
cv2.waitKey(0)
cv2.destroyAllWindows()
- 영상 합성
import cv2
import numpy as np
# 첫 번째 영상 로드
image1 = cv2.imread('image1.jpg')
# 두 번째 영상 로드
image2 = cv2.imread('image2.jpg')
# 영상 합성
blended_image = cv2.addWeighted(image1, 0.5, image2, 0.5, 0)
# 결과 이미지 출력
cv2.imshow('Blended Image', blended_image)
cv2.waitKey(0)
cv2.destroyAllWindows()
'PYTHON' 카테고리의 다른 글
| 1. python _ opencv (0) | 2023.05.18 |
|---|